ASR+LLM+TTS水平评估平台可在世界上第一个模型AI评
- 编辑:admin -ASR+LLM+TTS水平评估平台可在世界上第一个模型AI评
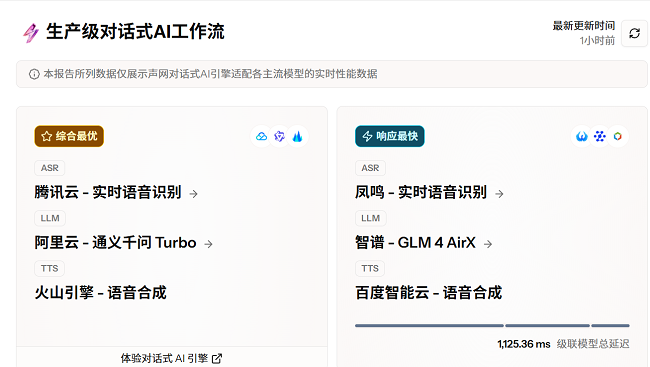 7月1日,Aoshi.com启动了世界上第一个AI模型评估平台(对话)。该平台提供了大型瀑布模型的对话对话方案的水平评估,该场景提供了声音网络电动机电动机的真实时间性能数据的更直观的愿景,并适应了每个常规模型的真实时间性能数据。同时,该平台还提供“竞技场”功能。此功能允许开发人员自由选择和比较ASR,LLM和TTS的常规供应商,并根据性能延迟数据的性能为您的业务选择适当的模型的供应商。当Aoshiwang对话框发行引擎时,它在开发人员中的灵活扩展方面很受欢迎。它与全球TTS的大型传统模型和供应商兼容,满足了各种商业场景和需求。这次,AI模型评估平台和AI引擎v1.6 dIlogue已被紧密地发射。对话AI引擎的新版本打开了ASR,并开始识别AO.com开发的实时语音。评估平台还允许开发人员在各种供应商之间进行选择,包括对腾讯云实时的语音识别,对火山引擎的真实时间语音识别,对真实时间语音的识别以及实时识别语音以比较懒惰数据。 ASR+LLM+TTS延迟性能分类列表是最佳,更快的响应模型。 AI模型评估平台主要分为两个功能:“仪表板”和“ Areland”。在“仪表板”中,官方建议是对话框进行调整后,越来越快的瀑布的模型组合的最佳组合。例如,到目前为止,推荐的瀑布模型的全面,最佳组合是云 + alibaba cloudtontiti hostenta -v中的真实语音识别O +火山引擎 - 语音合成。最快的级联模型组合是实时的风速识别 + Zhisou-gm 4 AIRX + BAID合成智能云语音,总延迟为1125.36毫秒。同时,董事会对AI对话方案的多个瀑布模型分类进行自定义,并且评估数据仍在每小时更新。 2。语音识别前3个(ASR):与最后一个单词的延迟作为评估指标的延迟。 3。语言模型(LLM)TOP 3:第一个单词延迟的性能数据分类。 4。前3个语音合成(TTS):每个TTS供应商的首次归因性能的比较。竞技场绩效比较模型的自主团队接受了TTS测试声明。 AI“竞技场”模型评估平台使开发人员可以独立选择不同的ASR,LLM和TTS模型来比较延迟性能。例如,LLM可以比较DeepSeek V3,Doubao Big MoDel,Zhipu GLM系列模型,Tongyi Qianwen系列模型,Minimax Text 01,Tencent Cloud Hunyuan系列模型等。电话识别ASR实时语言和TTS-VOICE的合成还包括常规市场模型。对于延迟数据指标,该平台比较了六个分位数的延迟数据的差异,包括P25,P50,P50至P99,这使开发人员能够了解有关每个模型的延迟数据性能的更深入信息。例如,大约50分钟的anfing-asr p的最后一个单词的thedelay为572毫秒。这意味着50%的证明懒数据少于572毫秒。此外,“竞技场” TTS发音的比较显示了几种不同场景的几种模型的发音:字母数字混合物,非流量陈述,客户服务,医疗和健康,健康,健康,销售,销售,销售,语音播客,Audomon Demonction votabulary的销售)。还提供了预先建立的歌词的证明句子还提供了反映综合质量的影响。当前,AI模型评估平台可在AOSHI官方网站上正式提供。将来,Aoshi将继续更新新的评估维度,例如模型的成本和单词的精度,从而使开发人员能够更好地选择模型的最佳组合来适应其业务。如果您想更多的AI模型评估平台实验,则可以访问官方AOSHI.com网站上的“ AI对话”页面以体验它。
7月1日,Aoshi.com启动了世界上第一个AI模型评估平台(对话)。该平台提供了大型瀑布模型的对话对话方案的水平评估,该场景提供了声音网络电动机电动机的真实时间性能数据的更直观的愿景,并适应了每个常规模型的真实时间性能数据。同时,该平台还提供“竞技场”功能。此功能允许开发人员自由选择和比较ASR,LLM和TTS的常规供应商,并根据性能延迟数据的性能为您的业务选择适当的模型的供应商。当Aoshiwang对话框发行引擎时,它在开发人员中的灵活扩展方面很受欢迎。它与全球TTS的大型传统模型和供应商兼容,满足了各种商业场景和需求。这次,AI模型评估平台和AI引擎v1.6 dIlogue已被紧密地发射。对话AI引擎的新版本打开了ASR,并开始识别AO.com开发的实时语音。评估平台还允许开发人员在各种供应商之间进行选择,包括对腾讯云实时的语音识别,对火山引擎的真实时间语音识别,对真实时间语音的识别以及实时识别语音以比较懒惰数据。 ASR+LLM+TTS延迟性能分类列表是最佳,更快的响应模型。 AI模型评估平台主要分为两个功能:“仪表板”和“ Areland”。在“仪表板”中,官方建议是对话框进行调整后,越来越快的瀑布的模型组合的最佳组合。例如,到目前为止,推荐的瀑布模型的全面,最佳组合是云 + alibaba cloudtontiti hostenta -v中的真实语音识别O +火山引擎 - 语音合成。最快的级联模型组合是实时的风速识别 + Zhisou-gm 4 AIRX + BAID合成智能云语音,总延迟为1125.36毫秒。同时,董事会对AI对话方案的多个瀑布模型分类进行自定义,并且评估数据仍在每小时更新。 2。语音识别前3个(ASR):与最后一个单词的延迟作为评估指标的延迟。 3。语言模型(LLM)TOP 3:第一个单词延迟的性能数据分类。 4。前3个语音合成(TTS):每个TTS供应商的首次归因性能的比较。竞技场绩效比较模型的自主团队接受了TTS测试声明。 AI“竞技场”模型评估平台使开发人员可以独立选择不同的ASR,LLM和TTS模型来比较延迟性能。例如,LLM可以比较DeepSeek V3,Doubao Big MoDel,Zhipu GLM系列模型,Tongyi Qianwen系列模型,Minimax Text 01,Tencent Cloud Hunyuan系列模型等。电话识别ASR实时语言和TTS-VOICE的合成还包括常规市场模型。对于延迟数据指标,该平台比较了六个分位数的延迟数据的差异,包括P25,P50,P50至P99,这使开发人员能够了解有关每个模型的延迟数据性能的更深入信息。例如,大约50分钟的anfing-asr p的最后一个单词的thedelay为572毫秒。这意味着50%的证明懒数据少于572毫秒。此外,“竞技场” TTS发音的比较显示了几种不同场景的几种模型的发音:字母数字混合物,非流量陈述,客户服务,医疗和健康,健康,健康,销售,销售,销售,语音播客,Audomon Demonction votabulary的销售)。还提供了预先建立的歌词的证明句子还提供了反映综合质量的影响。当前,AI模型评估平台可在AOSHI官方网站上正式提供。将来,Aoshi将继续更新新的评估维度,例如模型的成本和单词的精度,从而使开发人员能够更好地选择模型的最佳组合来适应其业务。如果您想更多的AI模型评估平台实验,则可以访问官方AOSHI.com网站上的“ AI对话”页面以体验它。